File Spoofing ist nach wie vor eine der effektivsten Techniken, die Angreifer einsetzen, um herkömmliche Sicherheitskontrollen zu umgehen. Letztes Jahr hat OPSWAT eine KI-verbesserte File Type Detection Engine eingeführt, um die Lücken zu schließen, die ältere Tools hinterlassen haben. In diesem Jahr haben wir mit dem File Type Detection Model v3 diese Fähigkeit erweitert, indem wir uns auf die Dateitypen konzentriert haben, bei denen Genauigkeit am wichtigsten ist und bei denen herkömmliche logikbasierte Systeme durchweg versagen.
Das OPSWAT File Type Detection Model v3 wurde speziell für die zuverlässige Klassifizierung von mehrdeutigen und unstrukturierten Dateien entwickelt, insbesondere von textbasierten Formaten wie Skripten, Konfigurationsdateien und Quellcode. Im Gegensatz zu allgemeinen Klassifizierern wurde dieses Modell speziell für Anwendungsfälle im Bereich der Cybersicherheit entwickelt, bei denen die falsche Klassifizierung eines Shell-Skripts oder die Nichterkennung eines Dokuments, das eingebettete Makros enthält, wie z. B. eine Word-Datei mit VBA-Code, ein erhebliches Sicherheitsrisiko darstellen kann.
Warum eine echte Dateityperkennung so wichtig ist
Die meisten Erkennungssysteme basieren auf drei gemeinsamen Ansätzen:
- Dateierweiterung: Diese Methode überprüft den Dateinamen, um den Typ anhand der Erweiterung zu bestimmen, z. B. .doc oder .exe. Sie ist schnell und weitgehend plattformübergreifend kompatibel. Allerdings ist sie leicht zu manipulieren. Eine bösartige Datei kann in eine sicher aussehende Erweiterung umbenannt werden, und einige Systeme ignorieren Erweiterungen vollständig, was diesen Ansatz unzuverlässig macht.
- Magische Bytes: Hierbei handelt es sich um feste Sequenzen, die am Anfang vieler strukturierter Dateien wie PDFs oder Bilder zu finden sind. Diese Methode verbessert die Genauigkeit gegenüber Dateierweiterungen, indem sie den tatsächlichen Dateiinhalt untersucht. Der Nachteil ist, dass nicht alle Dateitypen gut definierte Bytemuster haben. Magische Bytes können auch gefälscht werden, und uneinheitliche Standards bei verschiedenen Tools können zu Verwirrung führen.
- Analyse der Zeichenverteilung: Bei dieser Methode wird der tatsächliche Inhalt einer Datei analysiert, um auf ihren Typ zu schließen. Sie ist besonders hilfreich bei der Identifizierung von lose strukturierten textbasierten Formaten wie Skripten oder Konfigurationsdateien. Sie bietet zwar einen tieferen Einblick, ist jedoch mit höheren Verarbeitungskosten verbunden und kann bei ungewöhnlichen Inhalten zu falsch positiven Ergebnissen führen. Außerdem ist es bei Binärdateien, die keine lesbaren Zeichenmuster aufweisen, weniger effektiv.
Diese Methoden funktionieren gut bei strukturierten Formaten, werden aber unzuverlässig, wenn sie auf unstrukturierte oder textbasierte Dateien angewendet werden. So kann beispielsweise ein Shell-Skript mit minimalen Befehlen einer einfachen Textdatei sehr ähnlich sein. Vielen dieser Dateien fehlen aussagekräftige Kopfzeilen oder konsistente Markierungen, so dass eine Klassifizierung auf der Grundlage von Bytemustern oder Erweiterungen nicht ausreicht. Angreifer nutzen diese Mehrdeutigkeit aus, um bösartige Skripte als harmlose Dokumente oder Protokolle zu tarnen.
Ältere Tools wie TrID und LibMagic wurden nicht für dieses Maß an Feinheiten entwickelt. Sie sind zwar für die allgemeine Dateikategorisierung geeignet, wurden aber für den Umfang und die Geschwindigkeit optimiert, nicht für die spezielle Erkennung unter Sicherheitsbedingungen.
Funktionsweise des File Type Detection Model v3
Der Trainingsprozess des File Type Detection Model v3 besteht aus zwei Stufen. In der ersten Stufe wird ein bereichsadaptives Vortraining mit Masked Language Modeling (MLM) durchgeführt, damit das Modell bereichsspezifische Syntax- und Strukturmuster lernen kann. In der zweiten Phase wird das Modell anhand eines überwachten Datensatzes, in dem jede Datei explizit mit ihrem tatsächlichen Dateityp annotiert ist, feinabgestimmt.
Der Datensatz ist eine kuratierte Mischung aus regulären Dateien und Bedrohungsbeispielen, die ein ausgewogenes Verhältnis zwischen realer Genauigkeit und Sicherheitsrelevanz gewährleistet. OPSWAT behält die Kontrolle über die Trainingsdaten und ermöglicht so eine kontinuierliche Verfeinerung für Formate, die für Sicherheitsoperationen am wichtigsten sind.
Die KI-Komponente wird präzise und nicht breit gefächert eingesetzt. Das File Type Detection Model v3 konzentriert sich auf mehrdeutige und unstrukturierte Dateitypen, mit denen herkömmliche Erkennungsmethoden nicht effektiv umgehen können, wie z. B. Skripte, Protokolle und lose formatierter Text, bei dem die Struktur inkonsistent oder nicht vorhanden ist. Die durchschnittliche Erkennungszeit bleibt unter 50 Millisekunden, was es effizient für Echtzeit-Workflows bei sicheren Datei-Uploads, Endpoint Enforcement und Automatisierungspipelines macht.
Benchmark-Ergebnisse
Wir haben die OPSWAT File Type Detection Engine mit führenden Tools zur Erkennung von Dateitypen anhand eines großen und vielfältigen Datensatzes verglichen. Der Vergleich umfasste F1-Bewertungen für 248.000 Dateien und etwa 100 Dateitypen.
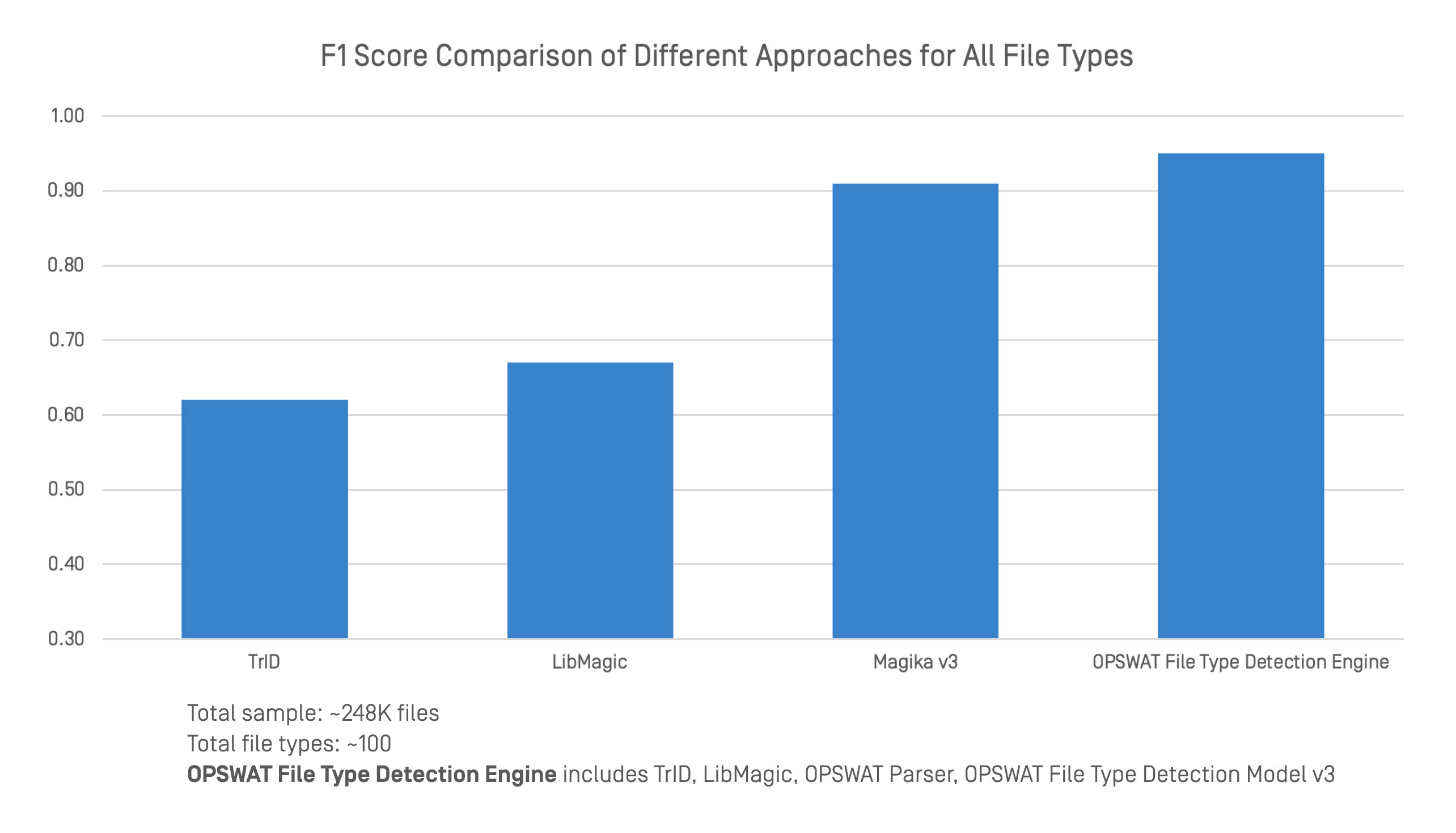
Die OPSWAT File Type Detection Engine integriert mehrere Techniken, darunter TrID, LibMagic und OPSWATeigene Technologien wie fortschrittliche Parser und das File Type Detection Model v3. Dieser kombinierte Ansatz liefert eine stärkere und zuverlässigere Klassifizierung sowohl für strukturierte als auch für unstrukturierte Formate.
In Benchmark-Tests erreichte die Engine eine höhere Gesamtgenauigkeit als jedes einzelne Tool. Während TrID, LibMagic und Magika v3 in bestimmten Bereichen gut abschneiden, sinkt ihre Genauigkeit, wenn Dateiköpfe fehlen oder der Inhalt nicht eindeutig ist. Durch die Kombination von traditioneller Erkennung und tiefgreifender Inhaltsanalyse erzielt OPSWAT eine gleichbleibende Leistung, selbst wenn die Struktur schwach oder absichtlich irreführend ist.
Text- und Skriptdateien
Text- und skriptbasierte Formate sind häufig in dateibasierte Bedrohungen und Seitwärtsbewegungen verwickelt. Wir haben einen gezielten Test mit 169.000 Dateien in Formaten wie den folgenden durchgeführt .sh, .py, .ps1, und .conf.
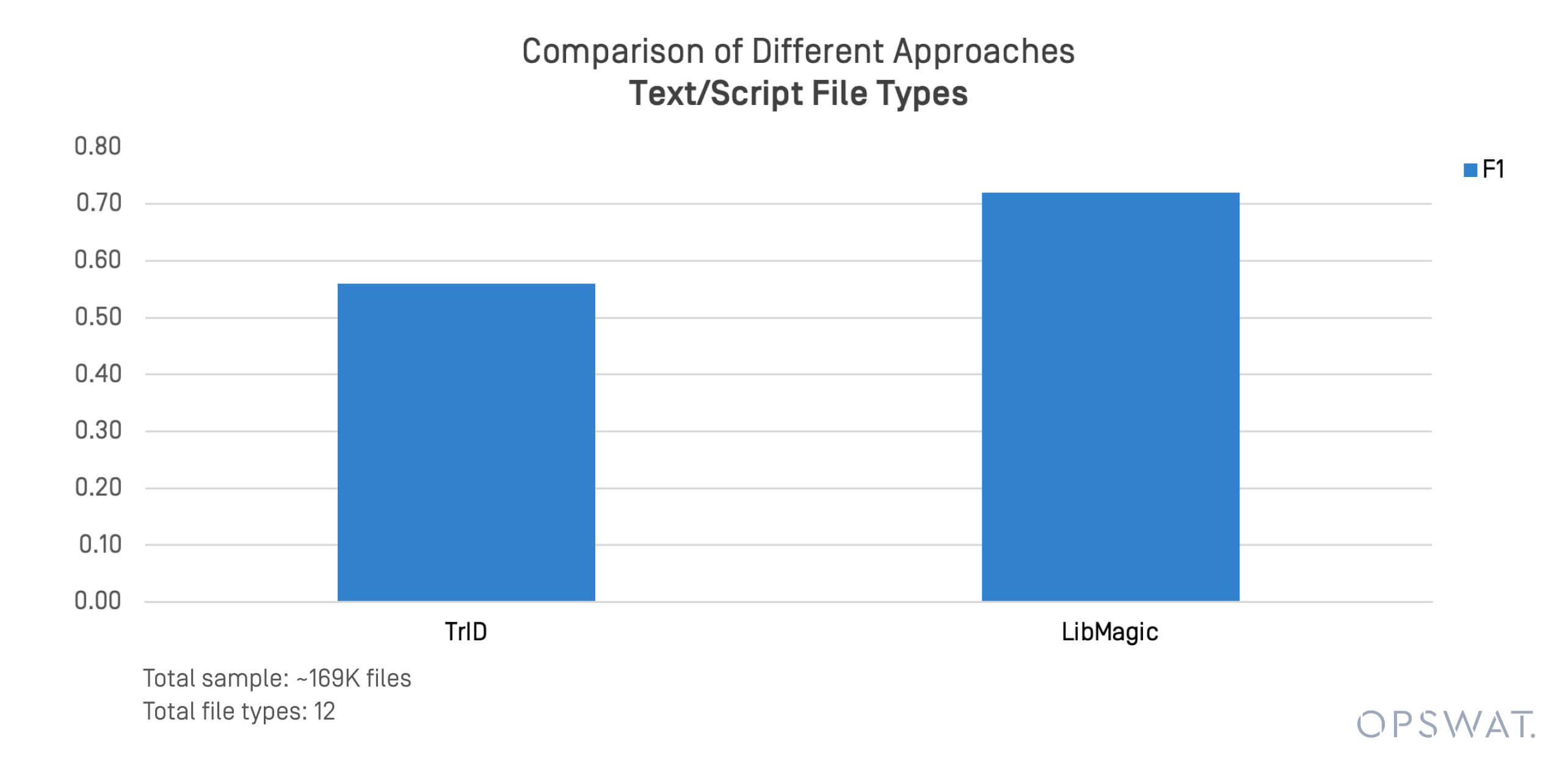
TrID und LibMagic zeigten Grenzen bei der Erkennung dieser unstrukturierten Dateien. Ihre Leistung nahm schnell ab, wenn der Dateiinhalt von den erwarteten Bytemustern abwich.
Dateityp-Erkennungsmodell v3 vs. Magika v3
Wir haben das OPSWAT File Type Detection Model v3 im Vergleich zu Magika v3, dem Open-Source-KI-Klassifikator von Google, für 30 Text- und Skript-Dateitypen mit demselben Datensatz von 500.000 Dateien bewertet.
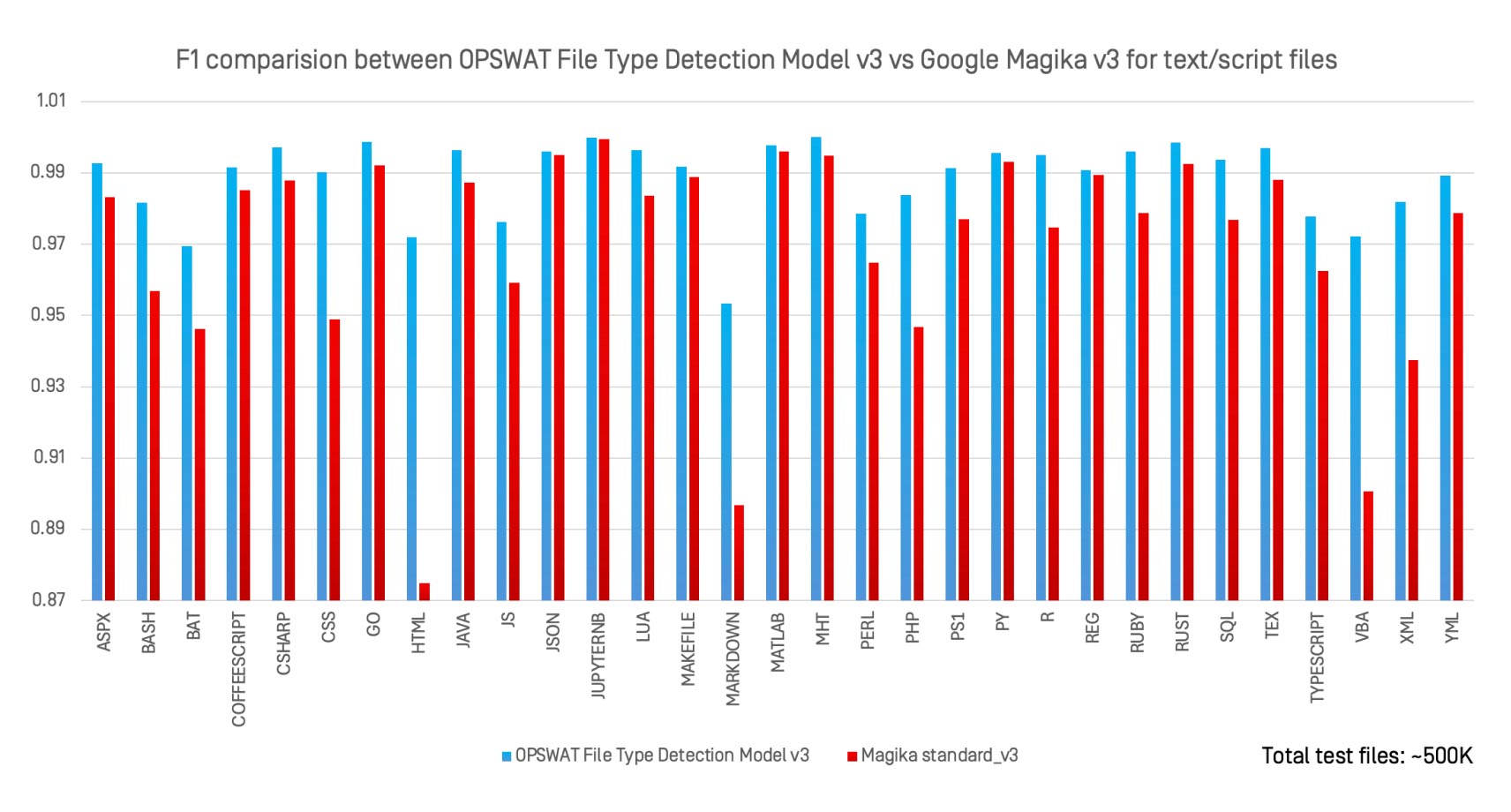
Wichtige Beobachtungen:
- Das File Type Detection Model v3 war bei fast allen Formaten gleich gut oder besser als Magika.
- Die stärksten Zuwächse gab es bei frei definierten Formaten wie
.bat, .perl, .html,und .xml. - Im Gegensatz zu Magika, das für die allgemeine Identifizierung entwickelt wurde, ist das File Type Detection Model v3 für Hochrisikoformate optimiert, bei denen eine falsche Klassifizierung schwerwiegende Sicherheitsauswirkungen hat.
Wichtigste Anwendungsfälle
Secure Hochladen, Herunterladen und Übertragen von Dateien
Verhindern Sie, dass getarnte oder bösartige Dateien über Webportale, E-Mail-Anhänge oder Dateiübertragungssysteme in Ihre Umgebung gelangen. Die KI-gestützte Erkennung geht über Erweiterungen und MIME-Header hinaus und identifiziert Skripte, Makros oder eingebettete ausführbare Dateien in umbenannten Dateien.
DevSecOps-Pipelines
Stoppen Sie unsichere Artefakte, bevor sie Ihre Software-Build- oder Deployment-Umgebungen verunreinigen. Durch die Validierung des wahren Dateityps anhand des tatsächlichen Inhalts stellt MetaDefender Core sicher, dass nur zugelassene Formate die CI/CD-Pipelines durchlaufen, wodurch das Risiko von Angriffen in der Lieferkette verringert und die Einhaltung sicherer Entwicklungspraktiken gewährleistet wird.
Durchsetzung der Vorschriften
Eine genaue Erkennung von Dateitypen ist für die Einhaltung gesetzlicher Vorschriften wie HIPAA, PCI DSS, GDPR und NIST 800-53, die eine strenge Kontrolle der Datenintegrität und Systemsicherheit erfordern, unerlässlich. Das Erkennen und Blockieren von gefälschten oder nicht autorisierten Dateitypen hilft bei der Durchsetzung von Richtlinien, die die Offenlegung sensibler Daten verhindern, die Revisionssicherheit aufrechterhalten und teure Strafen vermeiden.
Abschließende Überlegungen
Allzweck-Dateiklassifikatoren wie Magika sind für eine umfassende Kategorisierung von Inhalten nützlich. Im Bereich der Cybersicherheit ist Präzision jedoch wichtiger als die Abdeckung. Ein einziges falsch klassifiziertes Skript oder ein falsch etikettiertes Makro kann den Unterschied zwischen Eindämmung und Kompromittierung ausmachen.
Die OPSWAT File Type Detection Engine liefert diese Präzision. Durch die Kombination von KI-gestützter Dateitypanalyse mit bewährten Erkennungsmethoden bietet sie eine zuverlässige Klassifizierungsebene, wo herkömmliche Tools versagen, insbesondere bei mehrdeutigen oder unstrukturierten Formaten. Es geht nicht darum, alles zu ersetzen, sondern die kritischen Schwachstellen in Ihrem Sicherheits-Stack mit kontextbezogener Echtzeit-Erkennung zu verstärken.

